Elasticsearch max disk usage. Graylog2 Tuning Guide 2019-02-02
ElasticSearch memory usage on centralized log clusters

Higher indexing performance usually means allowing more segments to be present and thus making the queries slightly slower. Checking the directories, I found that the shards are taking around 10 times the size of the shard on the disk. Disk-based shard allocation Elasticsearch considers the available disk space on a node before deciding whether to allocate new shards to that node or to actively relocate shards away from that node. I'm much more worried about stability at the moment, hence my question regarding if I should be worried about the memory usage I'm seeing. Does key name length has impact on disk usage. Note that garbage collection count is cumulative, so the longer a node has been running, the higher this number will be.
diskspace
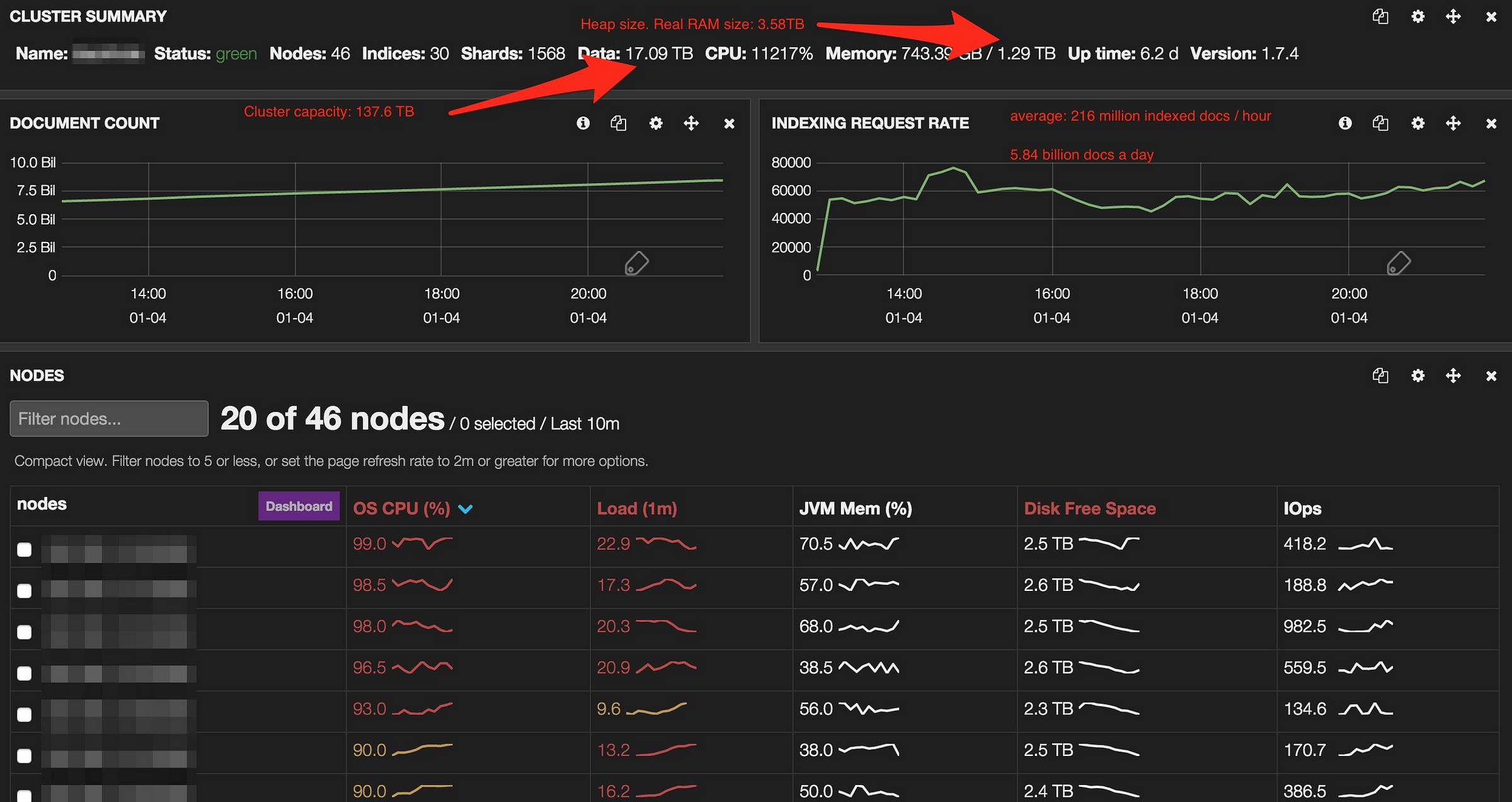
Our optimized code to insert records in a pool of 25 parallel threads could write only up to 3-4M records per hour, so obtaining a single data point involving 20M records could take 5-6 hours. It then checks to see whether loading the required fielddata would push the total fielddata size over the configured percentage of the heap. I'm much more worried about stability at the moment, hence my question regarding if I should be worried about the memory usage I'm seeing. Number of Elasticsearch nodes dropping left causing increase in query latency right Putting the request latency together with the request rate into a graph immediately provides an overview of how much the system is used and how it responds to it. Beyond that, as long as searches do not time out, I'd be happy. For this reason, it defaults to a fairly conservative 60%.
Disk usage elasticsearch
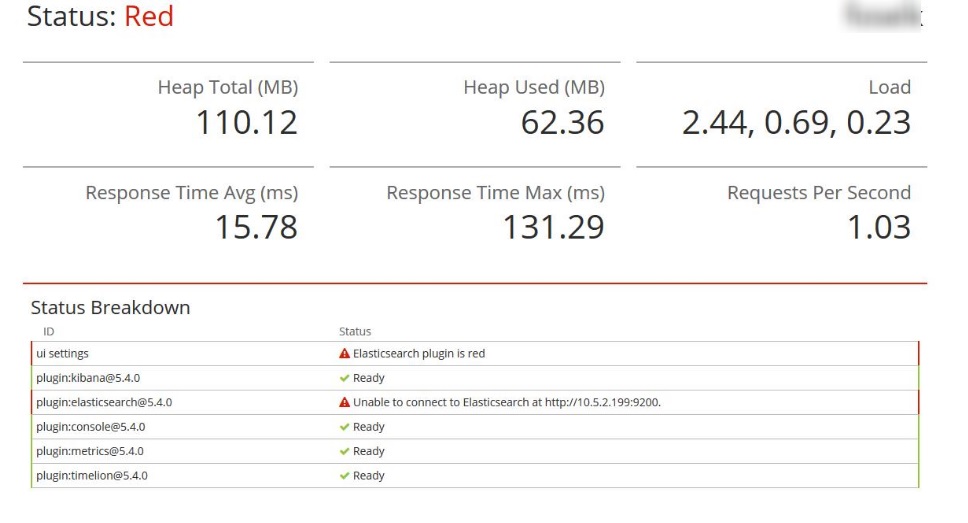
Mostly what I will be storing is logs from tomcat, apache and 70+ web apps. When a node fails the shards are reallocated to other nodes if there are existing replicas and enough available disk. Force Merge Indices in Elasticsearch are stored in one or more shards. While every precaution has been taken in the preparation of this content, the publisher and authors assume no responsibility for errors or omissions, or for damages resulting from the use of the information contained herein. See for more info about the Jenkins project. Each property has its own set of possible values but all sets are of the same size. To increase the size of your shards, you can decrease the number of primary shards in an index by with less primary shards, creating less indices e.
ElasticSearch memory usage on centralized log clusters

This is mostly helpful to save disk space since integers are way easier to compress than floating points. We felt like we were not moving closer to a general formula which would cover all corner cases. It also tells you how many times the circuit breaker has been tripped. Can someone please either give me some tips or point me to some documents? We are happy to announce the immediate availability of Elasticsearch 6. Once stripped of all commented lines, it looks like: cluster.
Elasticsearch 6.0 now available on Amazon Elasticsearch Service

It provides metrics about your clusters, nodes, and indices, as well as information related to your queries and mappings. In some cases we need much less than 0. Does not include console logs or artifacts. Evictions are costly, and this effectively schedules evictions on purpose, for no real gain. To unsubscribe from this group and stop receiving emails from it, send an email to. Most people assume fielddata is only loaded for those 100 documents. Text fields are not used for sorting and seldom used for aggregations although the is a notable exception.
ElasticSearch memory usage on centralized log clusters
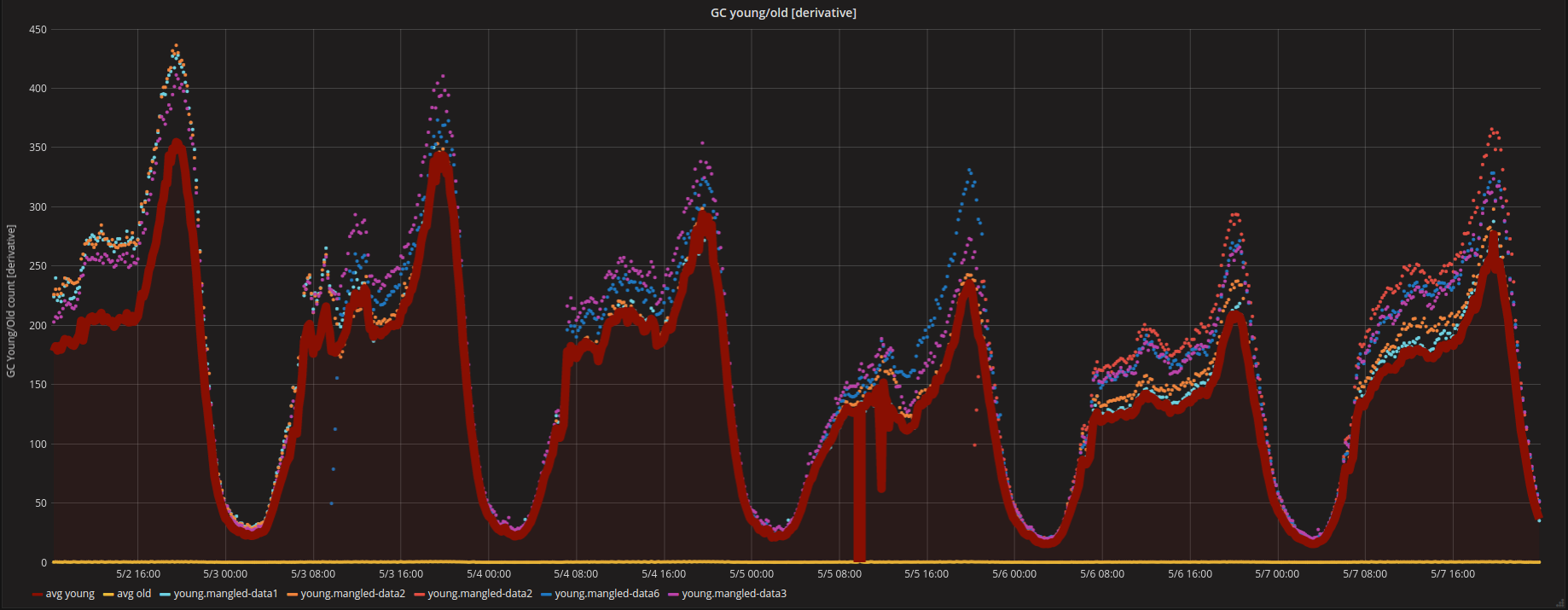
Can someone please either give me some tips or point me to some documents? This means that it can be searched, but not retrieved. In the graph below, we see a healthy sawtooth pattern clearly showing when major garbage collection kicked in. Would the other indices continue to serve? New records and updates are put first into new, small segments. If the estimated query size is larger than the limit, the circuit breaker is tripped and the query will be aborted and return an exception. This should be helpful to anyone new to Elasticsearch, and also to experienced users who want a quick start into performance monitoring of Elasticsearch.
Disk usage should report min/max values for multiple paths · Issue #13106 · elastic/elasticsearch · GitHub

If your storage size exceeds, then grow horizontally! Flush: but not too often Indexing is the process of storing and making a document searchable; however, just because a document is indexed does not mean that it is available in search — yet. In practice, it would have a negative impact to query performance by doing so. Mostly what I will be storing is logs from tomcat, apache and 70+ web apps. Nevertheless, the pattern can still be recognized, probably because all nodes in this cluster were started at the same time and are following similar garbage collection cycles. We observed the impact of that parameter on the average document size.
graylog

In the command below, we are querying two nodes by their names, node1 and node2 node. We will look at when to set this value, but first a warning: This setting is a safeguard, not a solution for insufficient memory. This is so that we can we validate that the settings are internally consistent that is, the low disk threshold is not more than the high disk threshold, and the high disk threshold is not more than the flood stage threshold. Although you keep older indices around, you seldom need to query them. Typically an id field will only need to be indexed as a keyword while a body field will only need to be indexed as a text field. Typical garbage collection sawtooth When we watch the summary of multiple Elasticsearch nodes, the sawtooth pattern is not as sharp as usual because garbage collection happens at different times on different machines. When it comes to actually using Elasticsearch, there are tons of metrics generated.
[elasticsearch] How to optimize disk usage?

To unsubscribe from this group and stop receiving emails from it, send an email to. This change intentionally slows down very broad searches and reduces their impact on other users. Done and that did indeed help a little. This is a bit unexpected result, since the values can be encoded in constant space as enum integers for low cardinality properties. Regards, Mark Walkom Infrastructure Engineer Campaign Monitor email: web: On 31 July 2014 19:16, Tim Stoop wrote: Hi all, We've been running an ElasticSearch cluster of three nodes since last December. This is a last resort to prevent nodes from running out of disk space. However, with the default settings, the fielddata from the old indices is never evicted! To prevent data loss you should have at least one replica.
Graylog2 Tuning Guide
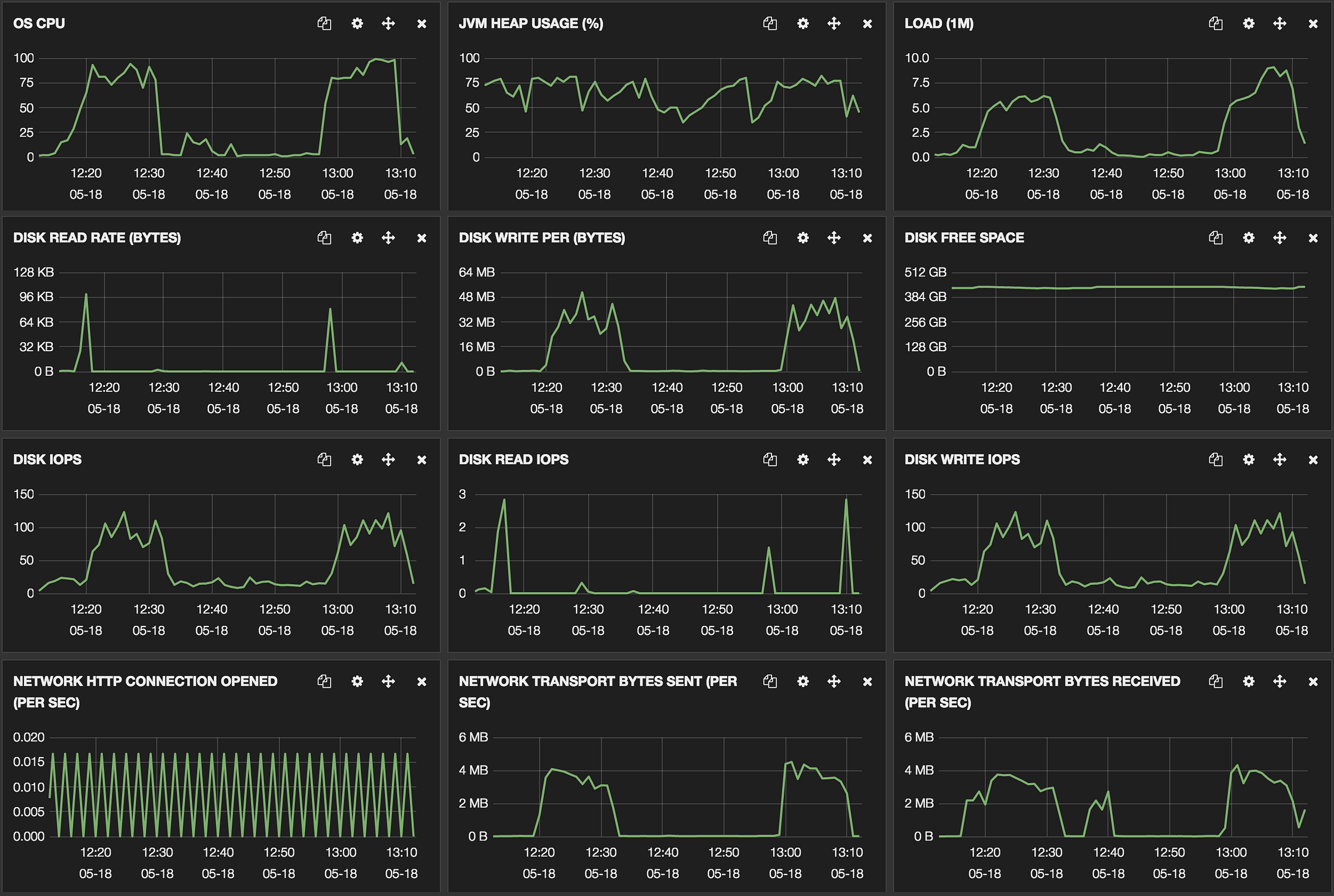
It defaults to 85%, meaning that Elasticsearch will not allocate shards to nodes that have more than 85% disk used. To learn more, see our. For instance it is very common that documents share the same field names, and quite common that they share some field values, especially on fields that have a low cardinality or a distribution. In other words, we are looking at how many bytes on average it takes to represent one character. The cost to pay is disk space. Suggestions cannot be applied while viewing a subset of changes. The Elasticsearch component provides a repository for various types of CloudBees Jenkins Enterprise data, such as raw metrics, job-related information, and logs.