Hash table in sql. Basics of Hash Tables Tutorials & Notes 2019-03-05
Hashtable
As the persisted value in the result column is used in other expressions the error becomes even more significant. When the table was created in the first example column nullability was explicitly defined. No external functions if you can avoid them! I appreciate any ideas at all. Use this hash value to build hash indexes. Create a table with a clustered columnstore index The following example creates a distributed table with a clustered columnstore index.
Troubleshooting Hash Indexes for Memory
Both types of temporary tables are created in the system database tempdb hi, It usually means a hash table served for temporary purpose, for example you can instantiate hash table object in memory which will be disposed when application exits. Local temporary tables are only available to the current connection to the database for the current user and are dropped when the connection is closed. This randomly generated text is called a salt in cryptography. They should be using views, derived tables, local table variables, temp tables. Under reasonable assumptions, the average time required to search for an element in a hash table is O 1. Another table storage option is to replicate a small table across all the Compute nodes.
Hash Tables

The default is the current database. This behavior is the default for Parallel Data Warehouse. Any deleted records would need to be closed off in a second statement. That's why clustered index are nonsense. Look at the image below for a graphical explanation. The storage size is the actual length of data entered + 2 bytes.
Hash Tables

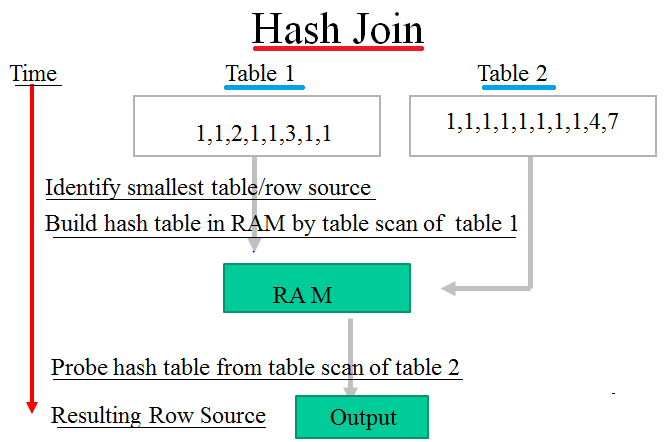
Of course the more collisions a function has the worse a function is because a large number of hash collisions can have a performance impact on read operations. I have written the following script for single column but I would like to know how to add values for multiple columns. Remember when I told you about chaining to solve collisions? This part of article has been already edited. The default value for n is 7. But it's present at index 3. In this case you can encrypt questions using symmetric keys, and decrypt them when needed.
Hash Tables
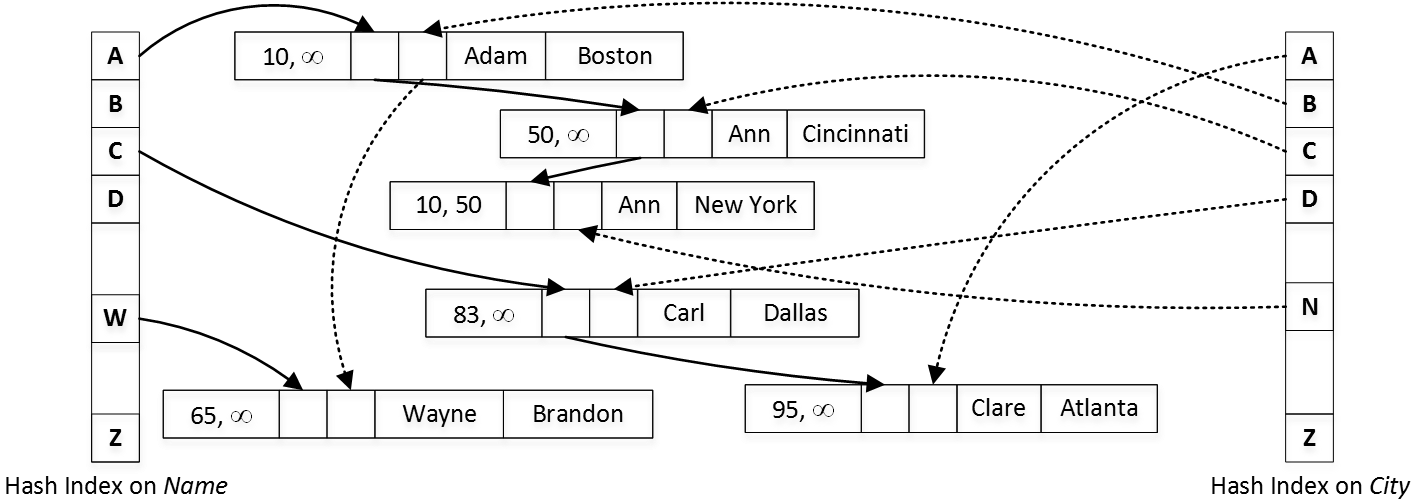
When a new entry has to be inserted, the hash index of the hashed value is computed and then the array is examined starting with the hashed index. Consider using a nonclustered index instead, Troubleshooting hash index bucket count This section discusses how to troubleshoot the bucket count for your hash index. You are required to count the frequency of all the characters in this string. The final table matches the original table. Chain lengths up to 10 are usually acceptable.
Hash Table in SQL Server?
This compensation may impact how and where products appear on this site including, for example, the order in which they appear. The table is specified with a three-part name, which starts with a. I always advocate limiting the number of rows transferred to something that is reasonable. In computing, performing a division to obtain the modulo is more expensive I mean it uses more cycles per instruction than a masking operation. All comments are reviewed, so stay on subject or we may delete your comment. In this tutorial you will learn about Hashing in C and C++ with program example.
Distributed tables design guidance
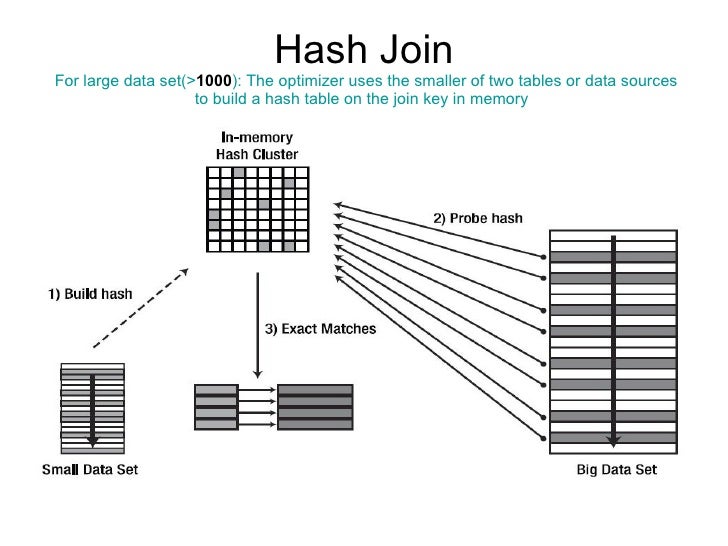
This can happen when the data is skewed. So, wrong user can't be authenticated. Alters to both temp tables and Hash table are logged on the transaction log. That's when index pointers for a row header come to light. But I think the underlying problem is the fact that you are trying to return 42,000 rows across your network. To avoid data movement during query execution, use the composite distribution column as a join column in queries. The clustered columnstore index affects how the data is stored within each distribution.
what is difference between temp table and hash table in sql server C# .NET
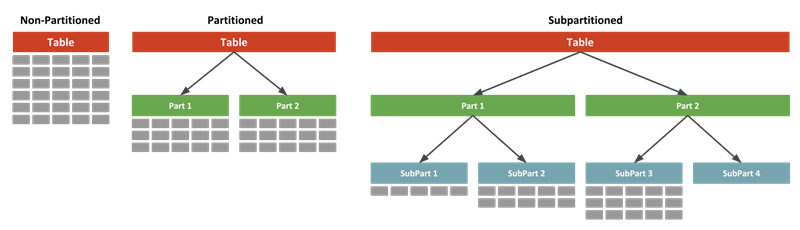
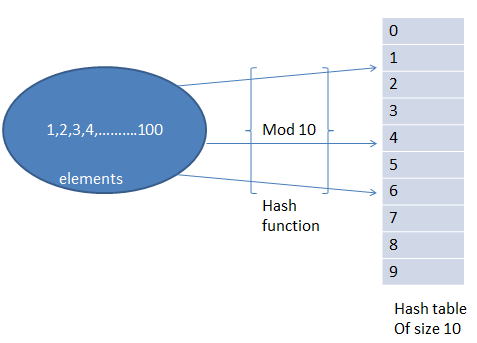
Joins can use additional columns without incurring data movement. This indicates that there is no such key in the table. The hash function will compute the same index for all the strings and the strings will be stored in the hash table in the following format. Choosing a distribution column A hash-distributed table has a distribution column that is the hash key. But using sha512 is better than nothing I suppose. This ensures that hash bailouts are not causing performance problems on your server. As mentioned before, a slight change in the input string of characters produces a completely different hashed output and this is what you could see in the second column.